Resume parsing
Software that turns unstructured CVs and profiles into structured fields in your ATS or CRM, usually with confidence scores and a human review path when extraction is uncertain.
Michal Juhas · Last reviewed May 3, 2026
What is resume parsing?
Resume parsing is the step where software reads CVs and job board profiles, then fills ATS fields like employer, dates, skills, and education. Good systems show confidence and route fuzzy rows to a human instead of silently guessing.
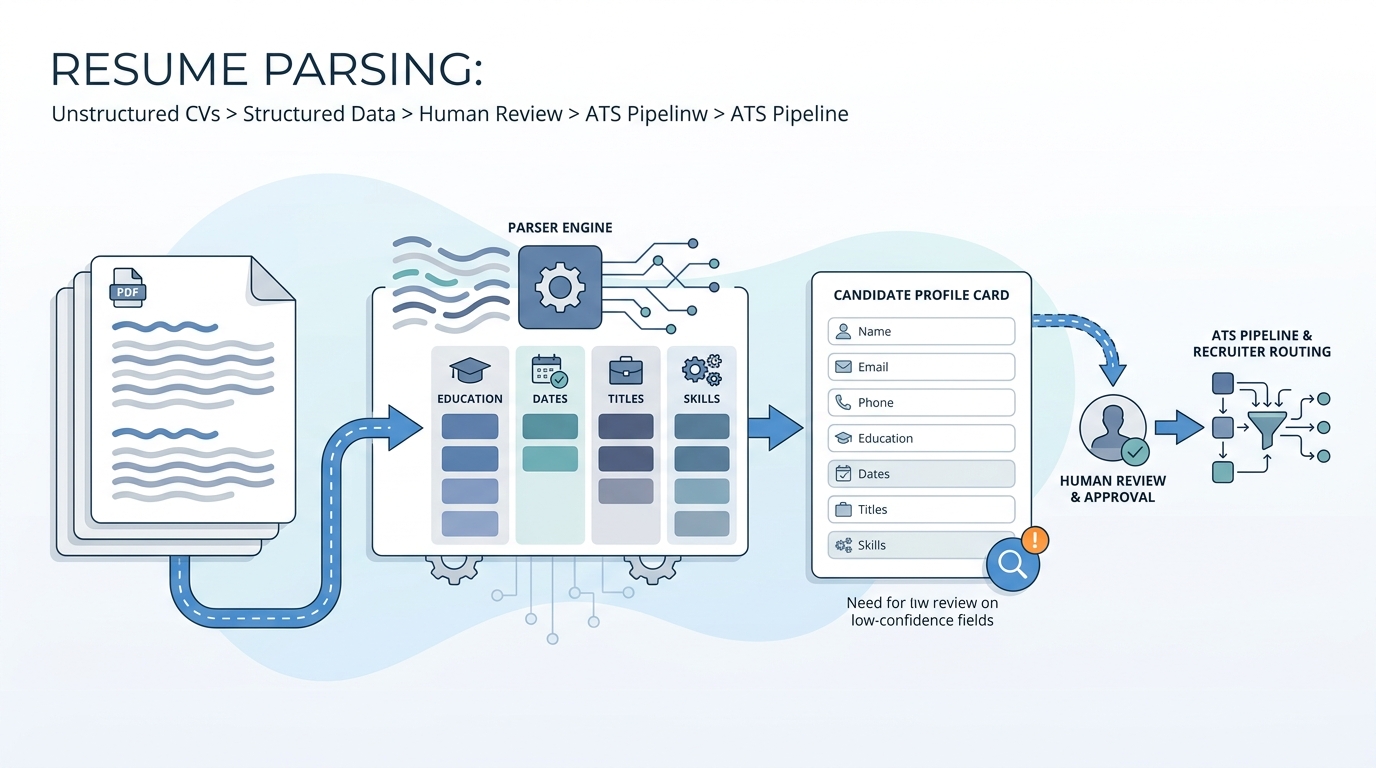
In practice
- Recruiters say "the parser mangled the title" when a two-column PDF collapsed into nonsense chips in the ATS.
- Engineers refer to "OCR plus NER" when discussing the same feature set vendors market as AI resume intelligence.
- TA ops schedules "reparse weekends" after vendor upgrades because historical rows suddenly need a new mapping.
Quick read, then how hiring teams use it
This is for recruiters, sourcers, TA, and HR partners who need the same vocabulary in debriefs, vendor calls, and policy reviews. Skim the first section when you need a fast shared picture. Use the second when you are deciding how it shows up in the ATS, sourcing tools, or candidate communications.
Plain-language summary
- What it means for you: Software reads CVs and drops answers into database fields your team searches and reports on.
- How you would use it: You tune field mappings, confidence thresholds, and review queues so recruiters trust the record.
- How to get started: Export fifty recent failures, tag them by layout type, and open a ticket batch with your vendor.
- When it is a good time: Before enabling auto-stage moves, after a template change, or when new languages launch.
When you are running live reqs and tools
- What it means for you: Parsing is the foundation under matching, ranking, and analytics. Weak fields poison everything above.
- When it is a good time: During ATS migration, when acquisition adds a new careers site, or when you add AI scoring downstream.
- How to use it: Pair technical metrics with recruiter correction time so finance sees full cost, not only accuracy charts.
- How to get started: Freeze new custom fields for one sprint while you remap exports and reindex search.
- What to watch for: Silent truncation, duplicate candidates after reparse, and multilingual resumes falling back to English-only heuristics.
Where we talk about this
Sourcing automation and AI in recruiting tracks both touch parsing when discussing inbound volume and compliance. Bring redacted samples to Workshops.
Around the web (opinions and rabbit holes)
Third-party creators move fast. Treat these as starting points, not endorsements, and double-check anything before you wire candidate data.
YouTube
- Search "resume parsing ATS" for vendor-agnostic walkthroughs of PDF layout problems and field mapping.
- Search "NER resume machine learning" for deeper technical primers if your engineering partners want shared vocabulary.
- r/recruiting and r/recruitinghell surface candidate-side frustrations when parsers drop degrees or garble names; read for empathy and QA ideas.
Quora
- Search "resume parser accuracy" for mixed quality threads; prefer answers that cite evaluation methodology over brand cheerleading.
Related on this site
- Glossary: Structured output, Candidate data enrichment, Semantic search
- Blog: AI candidate screening
- Workshops: Workshops
