Reverse sourcing workflow
A sourcing sequence that starts with verified contact data from enrichment providers or internal databases, then identifies which candidates from that set match the job criteria, before touching LinkedIn or sending any outreach.
Michal Juhas · Last reviewed May 4, 2026
What is a reverse sourcing workflow?
A reverse sourcing workflow flips the usual sourcing sequence. Instead of starting with a LinkedIn search and hoping to find contact details, you begin with a pool of records that already include verified contact information, then filter and rank that pool against the job criteria before sending a single message.
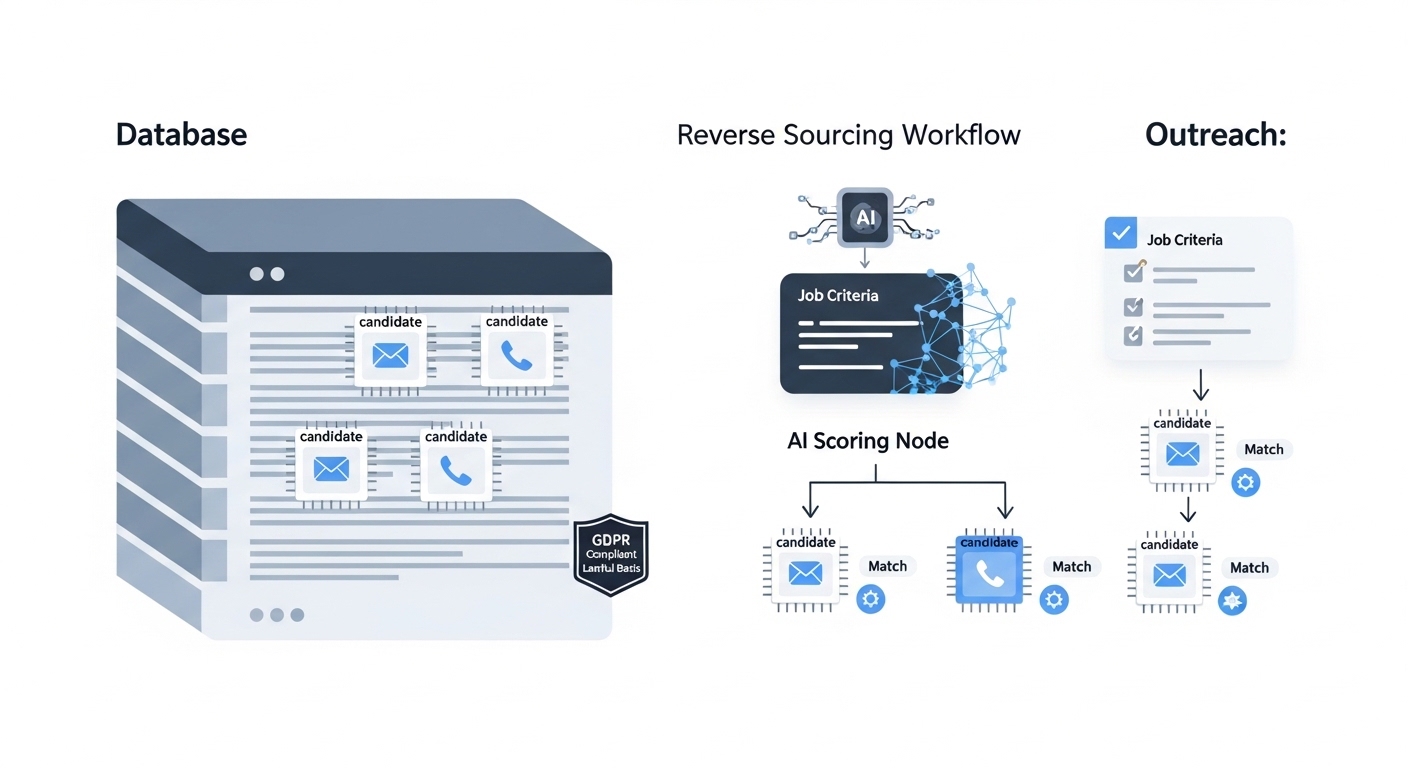
In practice
- A sourcer building a pipeline for a manufacturing quality manager role finds that LinkedIn response rates are below 5 percent for this audience. She uses a data provider to pull 800 records matching job title and geography, runs an email verification step, and scores the remaining 600 against four criteria. She contacts the top 40 directly via email rather than InMail.
- A TA team rebuilding a pipeline after a cancelled req uses their ATS past-applicant records as the starting pool. The candidates already consented to being contacted, so GDPR lawful basis is clear. An LLM re-scores the old profiles against the updated job criteria and surfaces 15 candidates worth re-engaging.
- A recruiter at an agency runs reverse sourcing against a commercial database and discovers that 30 percent of the contact records bounce. She adds a verification step and a bounce threshold rule before any campaign goes live.
Quick read, then how hiring teams use it
This is for recruiters, sourcers, TA, and HR partners who need the same vocabulary in debriefs, vendor calls, and policy reviews. Skim the first section when you need a fast shared picture. Use the second when you are deciding whether reverse sourcing fits your data access, compliance posture, and the role type you are filling.
Plain-language summary
- What it means for you: Instead of searching for profiles and then hunting for a way to reach them, you start with a database of people you can already contact, then decide which ones match the job.
- How you would use it: Pick a data source (a provider, your ATS past applicants, or an alumni list), filter by role-relevant criteria, verify contact data, and reach out through email or phone rather than LinkedIn InMail.
- How to get started: Pull a small batch from your ATS past-applicant records for a role you have filled before. Score them against the new job criteria. See how many match and how the email addresses hold up under a deliverability check.
- When it is a good time: When your target audience has low LinkedIn activity, when InMail response rates are poor, or when you have a warm database of past applicants or community members to reactivate.
When you are running live reqs and tools
- What it means for you: Reverse sourcing at scale requires a data contract, a scoring setup, a verification step, and a compliant first-touch email sequence. Each has a failure point. The workflow produces reliable output only when all four work together.
- How to use it: Score the record pool against explicit criteria rather than implicit preferences. Use contact enrichment to verify emails before sending. Set a daily send cap and a follow-up window so interested candidates receive a timely response.
- How to get started: Evaluate your data provider on coverage for the specific role type and geography you are filling, not on headline record counts. A provider with 50 million records but poor coverage for your segment is worse than a niche provider with 500,000 verified records in that segment.
- What to watch for: Stale contact data producing bounce rates above 5 percent, GDPR compliance gaps when the data source cannot explain how it obtained records, and scoring that reflects data availability rather than actual fit because the provider uses inconsistent job title conventions.
Where we talk about this
On AI with Michal live sessions, reverse sourcing workflow comes up in the sourcing automation track when discussing how to build pipelines without depending on LinkedIn InMail as the primary outreach channel. The session covers data provider evaluation, AI scoring, and compliant first-touch email setup. Start at Workshops and bring your current data access situation (which providers or internal databases you have) and the role types you find hardest to source through LinkedIn.
Around the web (opinions and rabbit holes)
Third-party creators move fast. Treat these as starting points, not endorsements, and double-check anything before you wire candidate data.
YouTube
- Search "reverse sourcing recruiting" for sourcer walkthroughs showing data-first workflows and how they compare to LinkedIn-first sequences on response rate.
- Glen Cathey and other advanced sourcing educators have covered data-layered sourcing approaches in conference recordings worth searching by name on YouTube.
- r/recruiting has threads on data providers, email deliverability, and whether reverse sourcing is worth the data contract cost for different role volumes.
- r/Talent covers sourcing strategy including when LinkedIn is not the right primary channel.
Quora
- Search "sourcing candidates without LinkedIn" for practitioner answers on data-first and community-first approaches that bypass LinkedIn dependency.
Reverse sourcing versus LinkedIn-first sourcing
| Dimension | LinkedIn-first | Reverse sourcing |
|---|---|---|
| Contact data | Found after profile identified | Verified before scoring begins |
| Response channel | InMail or connection request | Email or phone |
| GDPR complexity | Lower for legitimate interest | Higher: data source provenance required |
| Best fit audience | High LinkedIn activity | Low LinkedIn activity or past applicants |
Related on this site
- Glossary: Talent data aggregators, Contact enrichment for sourcing, Outbound talent sourcing, Proprietary talent pool, GDPR and first-touch outreach, Candidate data enrichment
- Blog: AI sourcing tools for recruiters
- Guides: Sourcers
- Live cohort: Workshops
- Membership: Become a member
