DeepSeek in recruiting
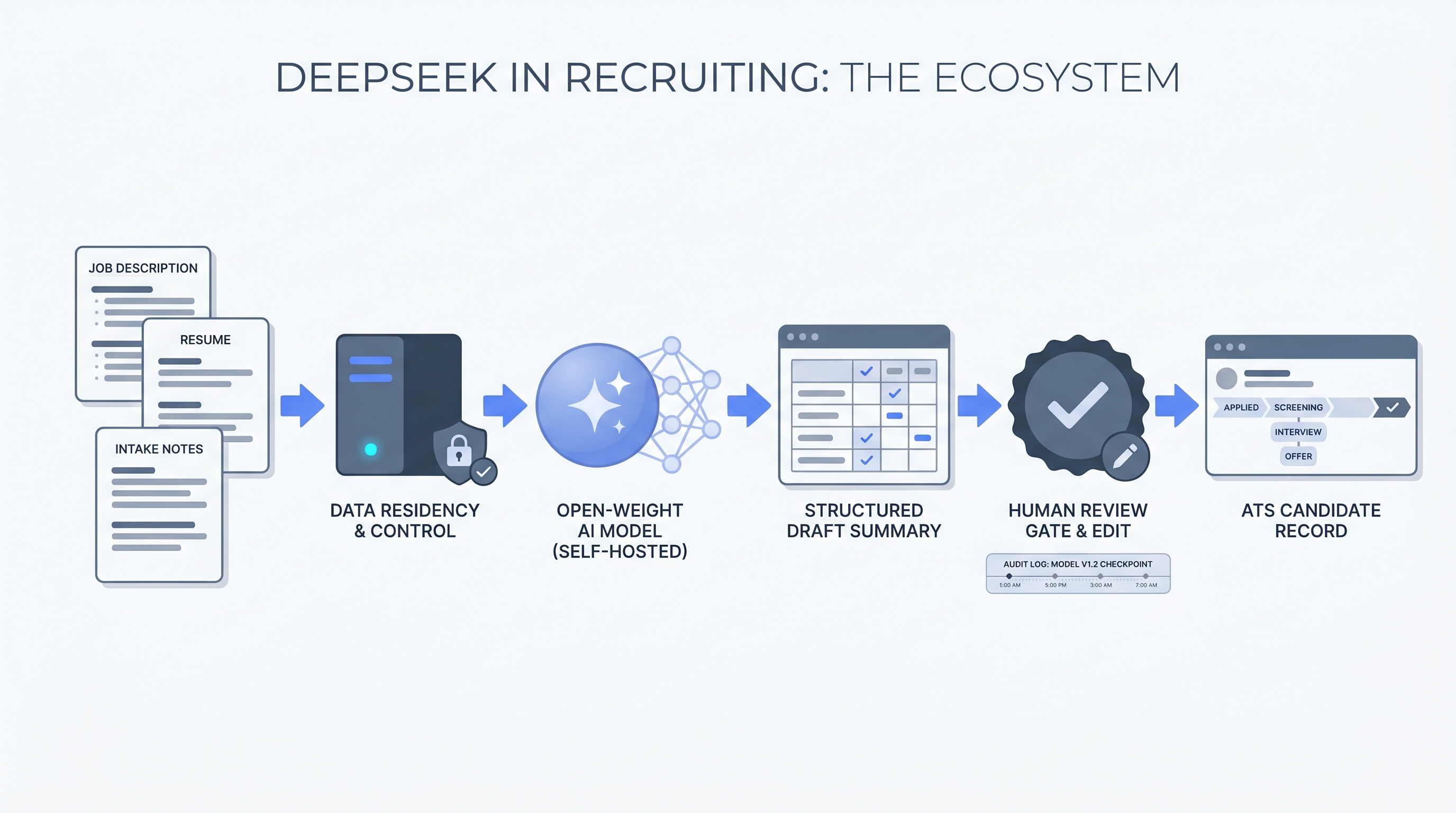
Using DeepSeek's open-weight language models to handle text-heavy recruiting tasks: drafting job descriptions, writing personalised outreach, summarising interviews, and screening large volumes of applications, often self-hosted by teams that cannot send candidate data to third-party cloud APIs.
Michal Juhas · Last reviewed May 5, 2026
What is DeepSeek in recruiting?
DeepSeek is a Chinese AI lab that releases open-weight language models, most notably DeepSeek-V3 and DeepSeek-R1, which teams can self-host or access via third-party providers. In recruiting, the term refers to using these models for the text-heavy production tasks that surround every req: drafting job descriptions from intake notes, writing personalised outreach for passive candidates, summarising interview transcripts, and screening large volumes of applications.
The term sits within the broader category of AI for recruiters but is specific to the deployment question that open-weight models raise. Because the model weights are publicly released, organisations can run DeepSeek on their own servers, which matters most for teams that cannot send candidate personal data to a third-party cloud API under their GDPR or security policy.
In practice
- A TA ops team at a regulated financial services firm runs DeepSeek-V3 on their own GPU cluster so that candidate CVs never leave the company network. They use it to draft screening summaries and outreach messages, with a reviewer approving each output before it touches the ATS.
- A sourcer at a mid-sized tech company describes a niche backend role in plain language and asks a DeepSeek model hosted by a EU-region cloud provider to generate Boolean strings and X-Ray queries. The model returns suggestions in under a minute; the sourcer removes false-positive synonyms before running them against their databases.
- A recruiter who says "we use DeepSeek self-hosted because our data cannot leave the building" is explaining the open-weight deployment decision to a hiring manager asking why the team doesn't just use a popular chat product.
Quick read, then how hiring teams use it
This is for recruiters, sourcers, TA, and HR partners who need the same vocabulary in debriefs, vendor calls, and policy reviews. Skim the first section when you need a fast shared picture. Use the second when you are deciding how DeepSeek or any open-weight model fits your daily workflow, your ATS, or your data governance policy.
Plain-language summary
- What it means for you: DeepSeek is a family of AI models where the underlying model file is publicly released, so your IT team can run it on your own servers instead of sending prompts and candidate data to a cloud provider.
- How you would use it: You write a prompt, paste intake notes or a candidate summary, and read the output critically before it goes anywhere near a candidate or an ATS record. The interface looks similar to ChatGPT, but the data path is entirely different when self-hosted.
- How to get started: Talk to your IT and legal teams first. Confirm whether your GDPR or security policy requires self-hosting or permits a DPA-covered third-party endpoint. Only then pick a deployment option and test prompts on non-personal data before processing real candidate files.
- When it is a good time: When your organisation cannot accept a cloud DPA, processes candidates at volume with meaningful per-token cost, or needs a pinned model version for audit reproducibility. Not the right choice when your team lacks internal ML ops support.
When you are running live reqs and tools
- What it means for you: Open-weight models like DeepSeek change the data residency equation: instead of relying on a vendor's DPA, your infrastructure team owns the security boundary. That shifts compliance accountability inward but removes vendor lock-in and per-token cost at scale.
- When it is a good time: After your IT team has confirmed a supported deployment path, your legal team has documented the lawful basis, and you have tested prompt reliability on at least two or three stable recruiting tasks. Before that point, use a proprietary model under a DPA rather than shipping candidate data to an unverified endpoint.
- How to use it: Set a system instructions-style opening prompt for each task type: your company name, the role, tone expectations, and any must-avoid phrases. Paste in the minimum data required and ask for a specific output format. Log which model version and checkpoint produced each output so you can revisit outputs if you upgrade the checkpoint later.
- How to get started: Start with a task that does not involve personal data, such as generating Boolean strings from a job description or drafting a generic outreach template. Move to candidate-specific tasks only after your deployment is confirmed compliant and your review process is documented. Review the AI outreach drafting entry for the outreach pattern specifically.
- What to watch for: Hallucinations on company names, titles, and dates when the model lacks sufficient input context. Checkpoint drift when you upgrade the model version and previously reliable prompts start producing different output quality. Data leakage risk if anyone on the team routes candidate CVs to the DeepSeek.com consumer endpoint without a DPA in place.
Where we talk about this
On AI with Michal live sessions, DeepSeek comes up in the model comparison conversation: open-weight versus proprietary, what data residency actually means for GDPR compliance, and when the self-hosting overhead is worth it. The AI in recruiting track covers prompting patterns and review habits across model types, while the sourcing automation track connects the same ideas to ATS integrations and workflow automation. If you want the full room conversation with a practitioner cohort, start at Workshops and bring a real deployment question so the discussion is grounded in your actual stack, not a generic tutorial.
Around the web (opinions and rabbit holes)
Third-party creators move fast on this topic. Treat these as starting points, not endorsements, and double-check anything before you wire candidate data through a workflow you found in a tutorial.
YouTube
- DeepSeek AI recruiting use cases for practitioner walkthroughs of prompt-to-draft flows and comparisons with proprietary model outputs across common recruiting tasks
- DeepSeek self-hosted local deployment for technical setup walkthroughs covering Ollama, GPU requirements, and data residency considerations for teams evaluating on-premise deployment
- Open source AI GDPR HR data privacy for compliance-focused discussions on what self-hosting actually changes and what it does not for HR data processing obligations
- r/recruiting: DeepSeek AI surfaces candid practitioner feedback on what output quality looks like in practice and where human editing effort is still required
- r/humanresources: open source AI GDPR covers the compliance side, including threads on self-hosting trade-offs and what a DPA actually covers for HR teams
- r/LocalLLaMA: DeepSeek recruiting for technical community views on prompt patterns, quantisation trade-offs, and GPU requirements when running open-weight models for business tasks
Quora
- How can DeepSeek AI be used in recruiting? collects early practitioner answers from sourcers and TA leaders (read critically; quality varies and not all contributors have deep recruiting backgrounds)
DeepSeek versus proprietary models for recruiting
| Dimension | DeepSeek (self-hosted) | Claude / ChatGPT (cloud) |
|---|---|---|
| Data residency | Stays on your infrastructure | Travels to vendor servers (DPA required) |
| GDPR lawful basis | Your infrastructure team owns the boundary | Vendor DPA covers processing under enterprise tier |
| Setup cost | High (GPU, ML ops, maintenance) | Low (API key or enterprise contract) |
| Per-token cost at volume | Fixed infrastructure cost | Variable per-token billing |
| Model version control | Your team controls checkpoint upgrades | Vendor updates without version pinning unless negotiated |
| Hallucination risk | Same as all LLMs; requires human review gate | Same as all LLMs; requires human review gate |
| Best fit | Regulated industries, high volume, air-gapped environments | Fast adoption, teams without ML ops support |
Related on this site
- Glossary: AI for recruiters, ChatGPT for recruiters, Claude in recruiting, Large language model, Hallucination, Human-in-the-loop, System instructions, AI outreach drafting, Workflow automation
- Blog: AI sourcing tools for recruiters
- Live cohort: Workshops
- Course: Starting with AI: the foundations in recruiting
- Membership: Become a member
