Deep web talent sourcing
Sourcing technique that finds candidates on publicly accessible but poorly indexed parts of the internet: code repositories, academic directories, conference speaker archives, portfolio platforms, and forum communities that standard job boards do not reach.
Michal Juhas · Last reviewed May 5, 2026
What is deep web talent sourcing?
Deep web talent sourcing means finding candidates on publicly accessible but poorly indexed parts of the internet that standard job boards and LinkedIn recruiter searches never reach: code repositories, academic institutional directories, conference speaker archives, open-source forums, and portfolio platforms where professionals describe their own work in their own words.
The term "deep web" here has nothing to do with the dark web or illicit activity. It refers to content that search engines index poorly or not at all: a researcher who keeps a lab page updated but hasn't touched LinkedIn in three years, an engineer whose public footprint is entirely in GitHub commit messages and a conference abstract, a designer whose only portfolio is on Behance.
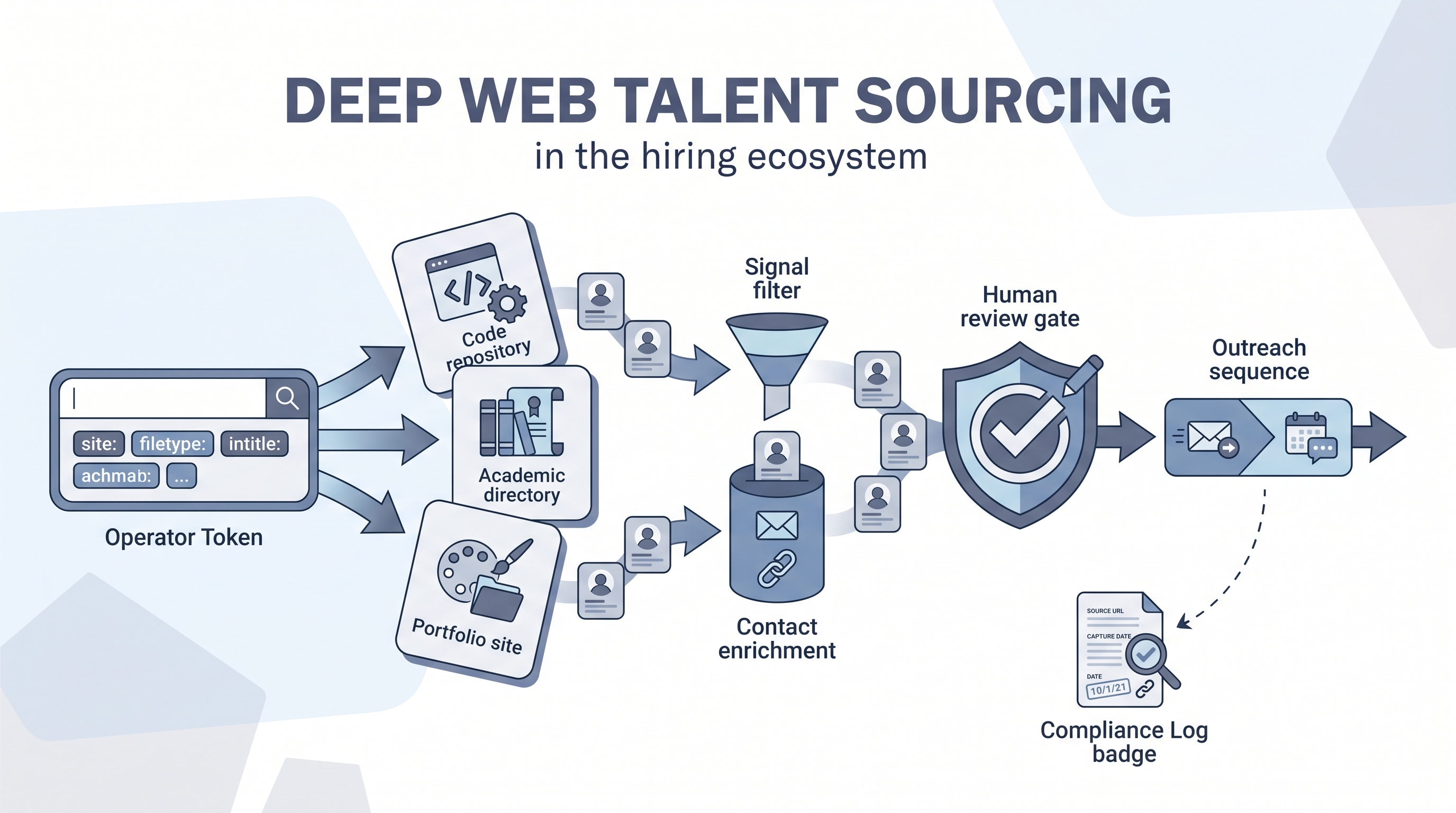
In practice
- A sourcer building a shortlist of embedded systems engineers uses
site:github.com "RTOS" "firmware"to find repositories with matching skill signals, then pulls profile names for enrichment before any outreach. - "X-ray LinkedIn" is the most common entry point for recruiters new to the technique: using Google operators to surface LinkedIn profiles by title and location without hitting the platform's own search limits.
- A technical sourcer notes in a debrief that three of their last five senior hires were initially found through GitHub or conference archives rather than any database. That is the business case that usually gets a team to invest time learning operators.
Quick read, then how hiring teams use it
This is for sourcers, recruiters, and TA leads who want a shared vocabulary when briefing hiring managers, reviewing sourcing methods, or evaluating new tools. Skim the first section for the fast picture; use the second when you are deciding whether the time investment is worth it for a specific req.
Plain-language summary
- What it means for you: Some candidates are not in LinkedIn or your ATS because they simply never maintained those profiles. Deep web sourcing finds them where they actually publish their work.
- How you would use it: Pick one req where standard searches keep returning the same pool. Write one Google X-ray string using the target platform (GitHub, ResearchGate, Behance) plus the core skill. Compare the names to your existing list.
- How to get started: Try
site:github.com "your target skill" "location"and read the first ten results. Notice how self-described expertise differs from LinkedIn keyword tags. - When it is a good time: When the same twenty names keep appearing in standard searches, when the role requires demonstrated work rather than self-reported skills, or when LinkedIn Premium returns no new results after two weeks.
When you are running live reqs and tools
- What it means for you: Deep web results surface faster and with richer skill evidence for niche technical, research, and creative roles. The tradeoff is manual cleanup: no standardized fields, inconsistent contact details, and GDPR obligations you need to document before any outreach.
- How to use it: Combine X-ray operators with contact enrichment for the verified contact step, and pipe cleaned profiles through a structured-output prompt to normalize the data before adding anyone to your ATS or outreach sequence.
- How to get started: Build one X-ray template for your most common hard-to-fill role family. Test it weekly so you know when Google changes its indexing of the target platform. Log the string, the date, and the result count so you can tune it with evidence rather than guesswork.
- What to watch for: AI tools that claim deep web sourcing often scrape LinkedIn, which violates its terms of service and creates legal risk. Check data source transparency before signing a contract. For GDPR, document your lawful basis and retention schedule for every source you add, not just the obvious ones.
Where we talk about this
On AI with Michal workshops, the sourcing automation track covers X-ray search alongside Boolean search and contact enrichment, with time for live string building on real roles. The AI in recruiting track connects deep web sourcing to responsible data use and how to brief hiring managers on source diversity. If you want the room conversation rather than only this page, start at Workshops and bring a specific role where your current search keeps returning the same names.
Around the web (opinions and rabbit holes)
Third-party creators move fast. Treat these as starting points, not endorsements, and verify anything before you wire candidate data.
YouTube
- Search "X-ray LinkedIn sourcing" and "Google site: operator recruiting" for hands-on string-building tutorials from sourcing practitioners. Videos from Boolean Strings practitioners and sourcing specialists show the technique applied to real role types.
- "Deep web sourcing recruiting" returns a mix of practitioner overviews and vendor demos. Prioritize videos that build strings live over ones that only name platforms, since string logic is the transferable skill.
- r/recruiting threads on "sourcing beyond LinkedIn" and "X-ray search" capture honest recruiter accounts of which operators still work and which have degraded with recent search engine changes.
- r/sourcing is a niche community where experienced sourcers share platform-specific strings and discuss compliance questions that rarely appear in vendor documentation.
Quora
- Search "how to source candidates not on LinkedIn" and "X-ray search for recruiters" for practitioner answers that explain when deep web sourcing is worth the extra effort versus when a vendor database subscription is faster.
Deep web versus open web sourcing
| Dimension | Open web (job boards, LinkedIn) | Deep web (X-ray, repositories, directories) |
|---|---|---|
| Profile structure | Standardized fields | Unstructured text, varies by platform |
| Contact details | Usually included | Often absent; enrichment required |
| Indexing | Fully crawled | Partial; operator strings required |
| Compliance effort | Moderate | Higher; source documentation required |
| Best for | High-volume standard roles | Niche, technical, and research roles |
| Freshness signal | Last-active date visible | Inferred from commit dates or posting dates |
Related on this site
- Glossary: Boolean search, Contact enrichment sourcing, Technical talent sourcing, GitHub talent sourcing, Candidate data enrichment, GDPR first-touch outreach, Human-in-the-loop (HITL), Outbound talent sourcing, Structured output
- Blog: AI sourcing tools for recruiters
- Guides: Sourcers
- Live cohort: Workshops
- Course: Starting with AI: the foundations in recruiting
- Membership: Become a member
