Explainable AI in hiring
Explainable AI in hiring means an AI tool can show, in plain language, why it scored, ranked, or flagged a candidate, so a recruiter can read the reasoning, challenge it, and demonstrate accountability for the outcome.
Michal Juhas · Last reviewed May 5, 2026
What is explainable AI in hiring?
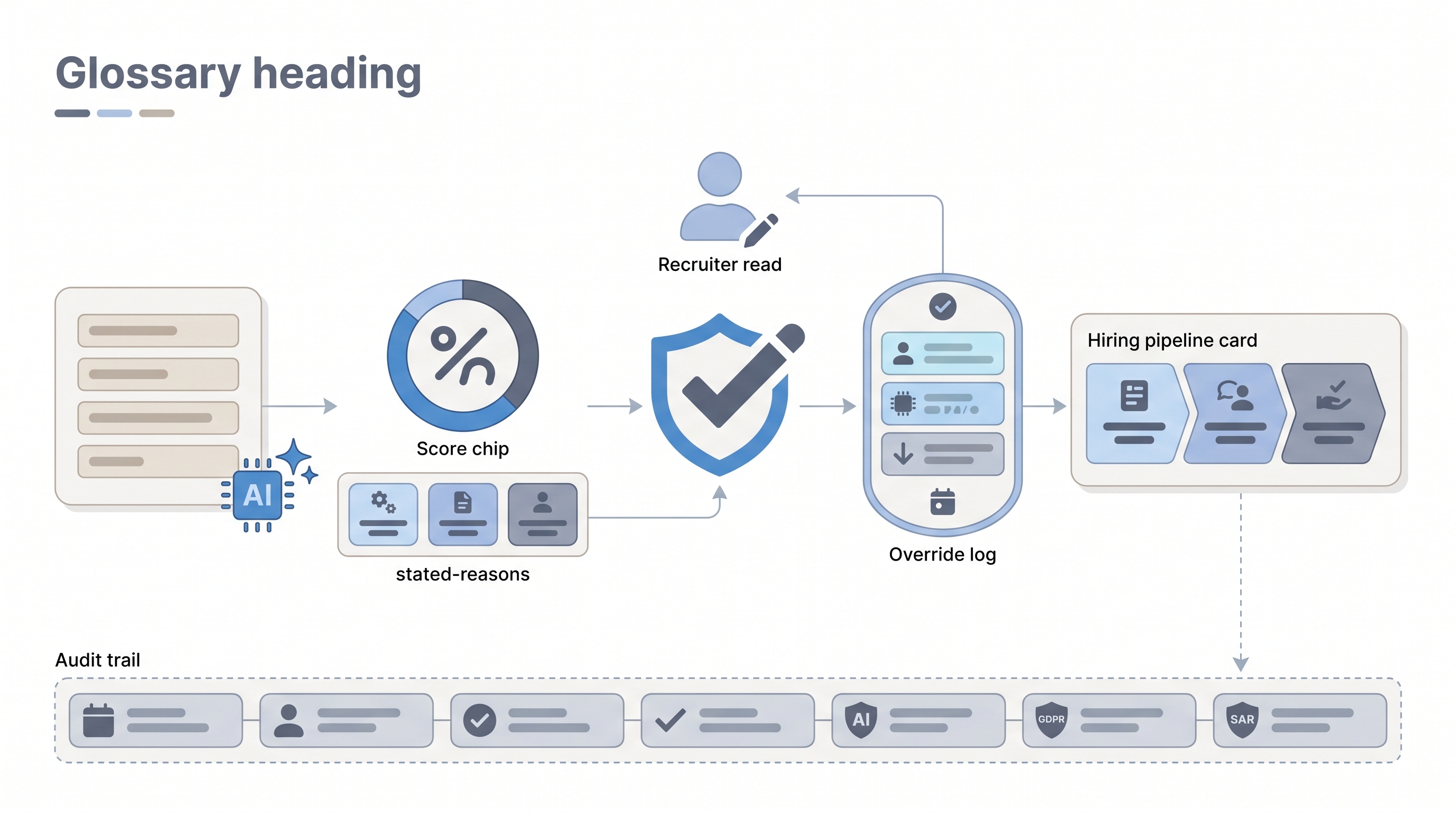
Explainable AI (XAI) in hiring means the tool can show a recruiter, in plain language, why it scored, ranked, or flagged a candidate. That explanation must be clear enough to read, act on, and override when it is wrong. A score of 87 with no context is not explainable. Matched on six years of direct sourcing experience, two role-specific skills, and a completed work sample is.
The stakes in hiring are high enough that trust the model is not a governance posture. GDPR Article 22, the EU AI Act's high-risk employment category, and emerging US state laws all assume you can produce a reason for each decision when a candidate or regulator asks. Explainability is how you build that answer before the question arrives.
In practice
- A recruiter reviewing an AI-ranked shortlist asks "why is this person first?" and the tool surfaces the job-criteria match factors rather than a raw number. That response is what XAI delivers at the stage level.
- TA legal teams in GDPR-scope organisations ask whether automated scoring triggers Article 22, then require vendors to document the model logic and store per-candidate explanations with a retention schedule.
- Hiring managers in debrief sometimes hear "the tool flagged low confidence on this candidate" and ask what low confidence means. If nobody on the team can answer, the model reasoning is not actually explainable yet.
Quick read, then how hiring teams use it
This is for recruiters, sourcers, TA, and HR partners who need the same vocabulary in debriefs, vendor calls, and policy reviews. Skim the first section when you need a fast shared picture. Use the second when you are deciding how to evaluate or configure an AI-powered hiring tool.
Plain-language summary
- What it means for you: When an AI tool ranks or scores a candidate, you can see the stated reasons in plain language, not just a number, so you know what to check and what to override.
- How you would use it: In a vendor demo, ask for a sample output and check whether it shows factors you could explain to a hiring manager or a candidate. If the answer is the vendor does not surface that, log it as a gap.
- How to get started: Add three questions to your next AI tool evaluation: What factors does this model explain? Where are those explanations stored? How long are they kept? Those three answers give you the legal and operational XAI baseline you need.
- When it is a good time: Before you expand any AI-assisted step from pilot to full deployment, and before you sign a vendor contract that involves scoring or ranking candidates.
When you are running live reqs and tools
- What it means for you: Explainability is operational, not a checkbox. Log the model's stated reasons alongside the recruiter's review decision so both are searchable if you receive a Subject Access Request or an adverse impact flag.
- When it is a good time: When adding any model to your sourcing or screening workflow, and whenever a vendor pushes a model update, because model drift can change which factors drive scores without notifying you.
- How to use it: Pair your AI bias audit cadence with a spot-check of per-decision logs. If a bias audit shows group disparity, explanations are how you trace which feature drove it. If you cannot trace it, the audit finding has nowhere actionable to go.
- How to get started: Build an override log into any AI-assisted step: reviewer ID, model version, stated reason, override yes or no, override note. A spreadsheet beats a system with no record at all.
- What to watch for: Post-hoc explanations (a second model explaining the first after the fact) can be misleading or entirely fabricated. Ask vendors whether explanations come from the decision model directly or from an explanation wrapper added afterward.
Where we talk about this
On AI with Michal live sessions, explainability comes up in the AI in recruiting track whenever we evaluate vendors or design review gates. Sourcing automation sessions connect it to human-in-the-loop log design and what a compliant debrief record looks like. If you want the full room conversation with real vendor demo practice, start at Workshops and bring your current tool stack for group review.
Around the web (opinions and rabbit holes)
Third-party creators move fast. Treat these as starting points, not endorsements, and double-check anything before you wire candidate data.
YouTube
- Explainable AI Explained (IBM Technology) is a clear vendor-neutral definition of XAI concepts that translates well to HR contexts.
- What is Explainable AI? walks through interpretability versus explainability and why the distinction matters for compliance.
- AI Bias and Fairness in Hiring covers how opaque models make bias harder to detect and correct, which is the practical case for explainability.
- Using AI to screen resumes - what are your experiences? in r/recruiting includes candid accounts of tools that return scores with no reasoning.
- AI bias in hiring in r/datascience covers the gap between aggregate fairness tests and per-candidate transparency.
- NYC Local Law 144 - what does this mean for recruiters? in r/recruiting is a practical thread on what US-based teams needed to change after the bias audit requirement.
Quora
- What is explainable AI and why does it matter? covers broad definitions with practitioner context that applies directly to hiring scenarios.
XAI versus related concepts
| Concept | Scope | Output |
|---|---|---|
| Explainable AI | Per decision | Plain-language factors for each score or rank |
| Bias audit | Aggregate | Pass-rate comparisons across groups |
| Auditability | Historical | Logs you can reconstruct after the fact |
| Human-in-the-loop | Governance | Named reviewer before action ships |
Related on this site
- Glossary: Human-in-the-loop, AI bias audit, Adverse impact, AI in recruiting, California AI employment decisions
- Blog: Boolean search vs AI sourcing
- Tools: AI hiring tools
- Live cohort: Workshops
- Course: Starting with AI: the foundations in recruiting
- Membership: Become a member
